人工智能(Artificial Intelligence,简称AI)已经从科幻小说中的想象变成了我们日常生活和工作中不可或缺的一部分。作为软件开发者,了解AI的发展历程不仅能帮助我们理解当前技术的来龙去脉,更能启发我们如何在自己的项目中创新性地应用这些技术。本文将带您穿越AI发展的关键时刻,从最初的理论构想到如今的大语言模型时代,全面梳理人工智能的演进脉络和技术突破。
人工智能的哲学基础与早期构想(1940s以前)
哲学思想与机器智能的初步探索
人工智能的概念远早于”人工智能”这一术语的诞生。自古以来,人类就一直思考着智能的本质以及是否可能创造具有思考能力的机器:
- 古希腊神话中的塔洛斯:一个由青铜制成的自动机器人,被赋予保护克里特岛的任务
- 莱布尼茨的逻辑计算器(1673):尝试将推理过程机械化,设想通过符号操作来解决争议
- 巴贝奇的分析机(1837):第一个通用计算设备的概念,虽未完成但提供了计算机先驱思想
- 布尔代数(1854):乔治·布尔创造的代数系统,为计算机科学的逻辑基础提供了数学工具
形式逻辑与计算理论的发展
20世纪早期,多项理论突破为AI的诞生提供了必要的数学和逻辑基础:
- 弗雷格的谓词逻辑(1879):创立了现代数理逻辑,允许更精确地表达复杂命题
- 哥德尔不完备定理(1931):证明了足够强大的形式系统中存在无法在系统内证明的真命题,对AI的理论边界产生深远影响
- 图灵机与可计算性理论(1936):艾伦·图灵提出了抽象计算机的概念,定义了算法可以解决的问题范围
- 冯·诺依曼架构(1945):提出了存储程序的计算机结构,为现代计算机奠定了基础
早期理论与萌芽期(1940s-1950s)
控制论与神经网络的初步构想
1940年代,跨学科研究开始为智能机器的构想提供具体方向:
- 控制论的提出:诺伯特·维纳(Norbert Wiener)在1948年出版《控制论:或关于在动物和机器中控制和通信的科学》,研究自动控制和通信系统的反馈机制,为智能系统提供了理论框架
- 麦卡洛克-皮茨神经元模型(1943):沃伦·麦卡洛克和沃尔特·皮茨提出了第一个数学模型,描述神经元如何通过”全或无”的方式工作,证明了这种简化的神经网络在理论上可以计算任何可计算函数
- 赫布学习理论(1949):唐纳德·赫布在《行为的组织》一书中提出了神经可塑性理论,解释了学习如何通过调整神经元连接强度发生,为后来的神经网络学习算法奠定了基础
图灵测试与计算智能的概念
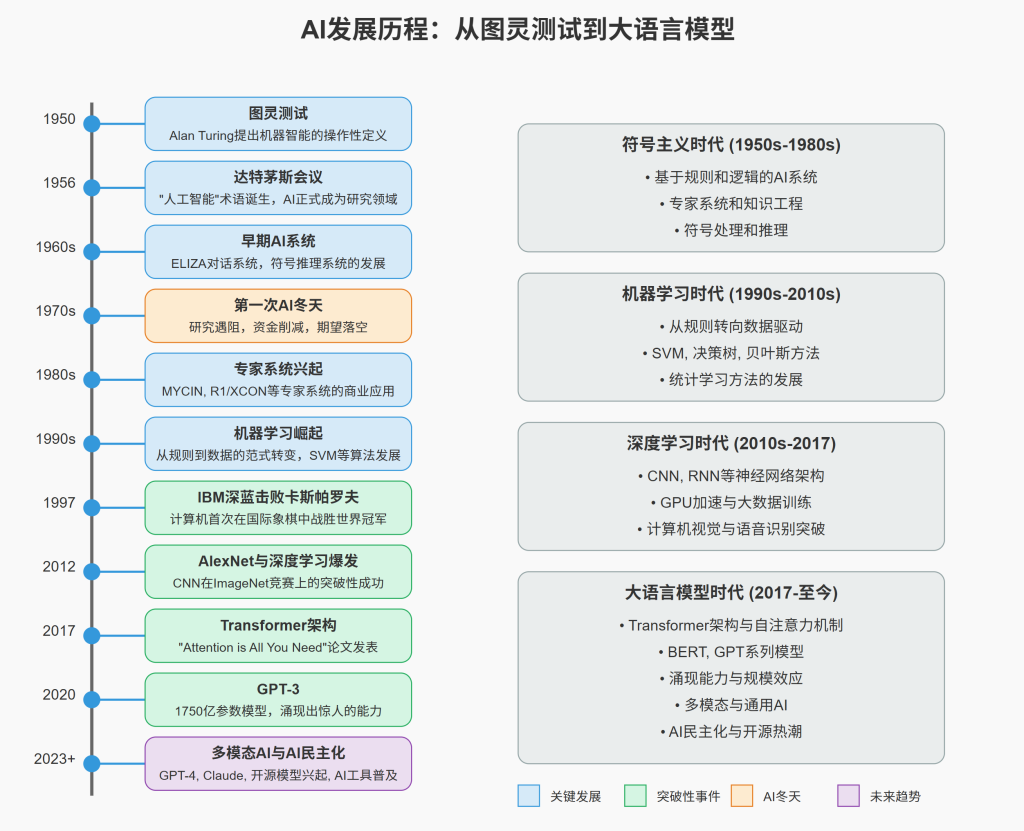
1950年,英国数学家艾伦·图灵(Alan Turing)发表了具有里程碑意义的论文《计算机器与智能》(Computing Machinery and Intelligence),其中:
- 提出了著名的”图灵测试”:如果一台机器能够与人类进行对话,并使人类无法区分对方是机器还是人类,那么这台机器就可以被认为具有智能
- 反驳了针对机器思考可能性的九大反对意见:包括神学、”脑袋埋在沙子里”、数学上的各种反对意见、意识论、能力的各种不足、非正规性、Lady Lovelace的反对意见、连续性论证和超感知能力等
- 讨论了创造思考机器的可能方法:包括编程模拟成人大脑、从”儿童机器”开始教育等路径
- 预测了未来计算机的能力:图灵预言在约50年后(即2000年左右),计算机将有可能通过图灵测试,而这一预测在某种程度上已经实现
图灵测试虽然后来受到各种批评(如中文房间思想实验),但它仍然是人工智能领域最具影响力的概念之一,为智能的操作性定义提供了框架。
第一个神经网络计算机:SNARC
1951年,玛文·明斯基(Marvin Minsky)和迪安·爱德蒙兹(Dean Edmonds)在普林斯顿建造了第一台神经网络计算机SNARC(随机神经模拟增强计算器)。这个设备使用了40个神经元,每个由真空管、电阻和电机组成,能够模拟老鼠在迷宫中寻找路径的行为。虽然功能有限,但它展示了神经网络实现的可能性。
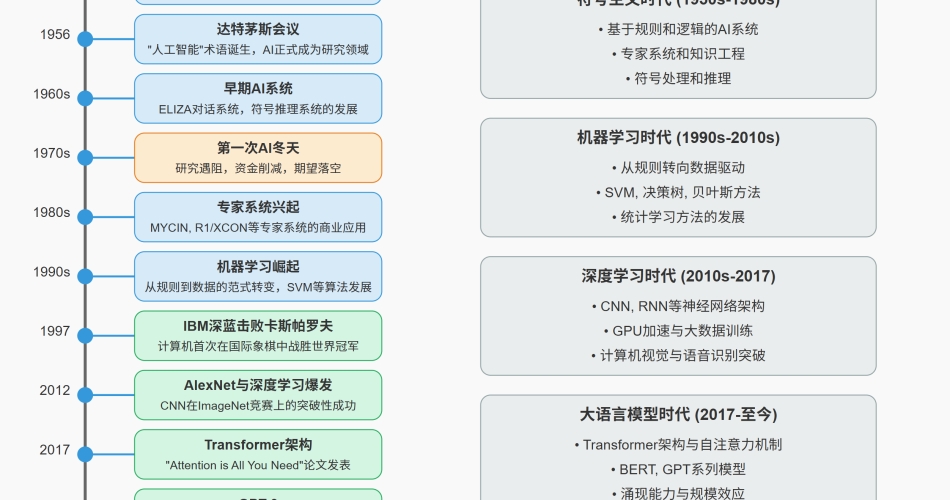
达特茅斯会议:AI学科的诞生
1956年夏天(7月至8月),在美国新罕布什尔州达特茅斯学院举行的一次为期两个月的学术会议上,”人工智能”(Artificial Intelligence)一词正式被约翰·麦卡锡(John McCarthy)提出并确立为一个研究领域。这次会议:
- 汇集了当时计算机科学领域的顶尖人才:包括约翰·麦卡锡、马文·明斯基、克劳德·香农(信息论创始人)、艾伦·纽厄尔、赫伯特·西蒙等
- 制定了研究议程:参与者雄心勃勃地计划在一个夏天内解决人工智能的基本问题,虽然这一目标过于乐观,但确立了关键研究方向
- 达成共识:”每一个学习的方面或智能的其他特征原则上都可以被精确地描述,使得机器可以对其进行模拟”
- 提出了多项基础性研究:包括符号推理、问题求解、机器学习等领域的初步工作
虽然会议的实际成果不如最初预期的那样丰富,但它成功地确立了人工智能作为一个独立的研究领域,并为后续几十年的研究方向奠定了基础。
初期发展与符号主义的黄金时期(1950s-1970s)
逻辑推理系统的突破
1950年代末至1960年代,人工智能研究主要集中在符号操作和逻辑推理系统上:
- 逻辑理论家程序(Logic Theorist,1956):由艾伦·纽厄尔、赫伯特·西蒙和克里夫·肖开发,被认为是第一个人工智能程序,能够证明《数学原理》中的38个定理,其中一个证明比原书更为优雅
- 通用问题求解器(General Problem Solver,1957):同样由纽厄尔和西蒙开发,旨在解决更广泛的问题类型,通过手段-目的分析(means-ends analysis)策略减少目标状态与当前状态之间的差异
- LISP编程语言(1958):约翰·麦卡锡创造的列表处理语言,成为早期AI研究的标准工具,其灵活的符号处理能力和递归特性使其特别适合AI应用
自然语言处理的早期尝试
1960年代初期,研究人员开始探索让计算机理解和生成人类语言的可能性:
- 机器翻译(1954-1966):冷战推动了自动翻译研究,尤其是俄语到英语的翻译,如乔治城大学自动翻译项目
- ELIZA(1964-1966):由MIT的约瑟夫·韦森鲍姆(Joseph Weizenbaum)开发,这是一个能模拟心理治疗师进行对话的程序,它通过简单的模式匹配和替换规则来”理解”输入并生成回应
- 工作原理:ELIZA识别输入文本中的关键词,并应用转换规则生成回应,如将”我感到伤心”转换为”为什么你感到伤心?”
- 社会影响:尽管韦森鲍姆强调ELIZA并不真正理解对话,但许多用户将情感投射到程序上,认为它具有理解能力,这一现象后来被称为”ELIZA效应”
- SHRDLU(1968-1970):由特里·温诺格拉德(Terry Winograd)开发,在一个简化的积木世界中理解和执行复杂的命令,展示了在受限环境下结合语言理解和规划的可能性
知识表示与专家系统的开端
1970年代,研究重点转向如何表示和使用领域知识:
- 语义网络(Semantic Networks):由罗斯·奎里安(Ross Quillian)在1966年提出,用图形结构表示概念之间的关系,为知识表示提供了直观的框架
- 框架理论(Frame Theory):马文·明斯基在1974年提出,将知识组织成结构化的单元(框架),每个框架包含属性(槽)和对应的值
- MYCIN系统(1972):由斯坦福大学的爱德华·肖特利夫(Edward Shortliffe)开发,用于诊断血液感染疾病,它包含约600条规则,在某些情况下的诊断准确率超过了一些医生
- DENDRAL系统(1965-1983):由斯坦福大学开发,用于推断有机分子的结构,被认为是第一个成功的专家系统,将化学领域专家知识编码为规则
计算机视觉与机器人学的起步
同时期,研究人员也在探索让机器”看见”和”行动”的可能性:
- 机器视觉:1966年,MIT的人工智能实验室启动了”夏季视觉项目”,希望在一个夏天内解决计算机视觉问题,虽然目标过于乐观,但推动了边缘检测、图像分割等基础技术的发展
- Shakey机器人(1966-1972):由斯坦福研究院开发的第一个能够推理自身行为的移动机器人,结合了感知、推理和行动能力
- “积木世界”:简化的环境中的视觉识别和机械手操作实验,如MIT的COPY DEMO系统能识别和堆叠积木
AI冬夏交替时期(1970s-1990s)
第一次AI冬天(1974-1980)
随着研究的推进,科学家们发现AI面临的挑战比最初想象的要复杂得多:
- 计算能力的限制:当时的计算机处理能力和存储容量严重不足,无法支持大规模的AI应用
- 组合爆炸问题:很多AI算法面临指数级的搜索空间,使得实际问题难以在合理时间内解决
- 知识表示的困难:对常识和背景知识的表示与推理远比预期复杂
- 莱特希尔报告(1973):英国科学研究委员会委托詹姆斯·莱特希尔爵士对英国的AI研究进行评估,报告严厉批评了AI研究的过度承诺和有限成果
- ALPAC报告对机器翻译的打击:1966年美国自动语言处理咨询委员会的报告导致机器翻译研究资金大幅削减
这些因素导致了研究进展放缓,政府和私人投资减少,许多AI项目被取消,这一时期被称为”第一次AI冬天”。
知识工程与专家系统的兴起(1980s)
1980年代,随着计算机性能的提升和知识工程方法的改进,AI研究重新获得了动力:
- 知识工程的方法论:爱德华·费根鲍姆(Edward Feigenbaum)提出将专家知识系统化地转化为计算机程序的方法
- 商业专家系统的成功案例:
- R1/XCON系统:由卡内基梅隆大学为数字设备公司(DEC)开发,用于配置VAX计算机系统,到1986年每年为DEC节省约4000万美元
- 美国运通的信用卡欺诈检测系统:能够分析交易模式识别潜在的欺诈行为
- PROSPECTOR:用于矿物勘探的专家系统,成功预测了价值数亿美元的钼矿床位置
- 专家系统开发工具的普及:如KEE(Knowledge Engineering Environment)、ART(Automated Reasoning Tool)和OPS5语言等工具降低了开发门槛
- 日本第五代计算机项目(1982-1992):雄心勃勃的国家项目,旨在开发基于并行逻辑编程的新一代智能计算机,虽然未达预期但推动了相关技术发展
第二次AI冬天(1987-1993)
然而,专家系统的局限性很快变得明显:
- 知识获取瓶颈:从专家那里提取和形式化知识是耗时且昂贵的过程
- 适应性差:专家系统难以适应领域知识的变化或处理未预见的情况
- 可扩展性问题:随着规则库的增长,系统性能下降和维护难度增加
- 缺乏真正的学习能力:大多数专家系统不能从经验中学习和改进
- 市场竞争:专用的Lisp机器无法与快速发展的通用工作站竞争
- 第五代计算机项目的失败:未能实现其宏伟目标,损害了公众对AI的信心
这些问题,加上经济衰退,导致了专家系统市场的崩溃,多家AI公司倒闭或被收购,研究资金再次大幅削减,这被称为”第二次AI冬天”。
机器学习的崛起(1990s-2000s)
从规则到数据驱动的范式转变
1990年代中期开始,AI研究范式发生了根本性转变:
- 从手工编码规则到基于数据的学习:研究者认识到,让机器从数据中学习规则比直接编程规则更有效
- 统计学习方法的复兴:贝叶斯网络、隐马尔可夫模型等概率方法重新受到重视
- 计算能力的显著提升:摩尔定律持续推动计算性能提升,为数据密集型算法提供支持
- 互联网带来的大量数据:Web的普及产生了前所未有的大规模数据集,为训练复杂模型提供了素材
机器学习算法的重要进展
这一时期出现了多项重要的算法创新:
- 支持向量机(SVM,1992-1995):由弗拉基米尔·瓦普尼克(Vladimir Vapnik)和科里娜·科特斯(Corinna Cortes)开发,提供了一种处理高维数据的强大方法,特别适合分类问题
- 决策树算法的改进:如C4.5(1993)和随机森林(2001)
- 提升(Boosting)方法:AdaBoost算法(1997)由约阿夫·弗洛伊德(Yoav Freund)和罗伯特·沙皮尔(Robert Schapire)提出,通过组合多个弱学习器创建强学习器
- 核方法(Kernel Methods)的发展:将线性算法扩展到非线性问题
- 概率图模型:如条件随机场(2001)为序列标注问题提供了强大工具
神经网络的复兴
神经网络研究在经历了1970年代的低谷后(受到马文·明斯基和西摩尔·帕帕特关于感知器局限性的批评),开始重新获得关注:
- 反向传播算法的重新发现与推广:虽然该算法早在1960-1970年代就被多人独立发明,但直到1986年杰弗里·辛顿(Geoffrey Hinton)等人的工作才广为人知
- 长短期记忆网络(LSTM,1997):由塞普·霍赫莱特(Sepp Hochreiter)和尤尔根·施密德胡伯(Jürgen Schmidhuber)提出,解决了循环神经网络处理长序列时的梯度消失问题
- 卷积神经网络的改进:杨立昆(Yann LeCun)等人在1989-1998年间开发的LeNet系列网络为手写字符识别等任务提供了实用解决方案
实用AI的标志性突破
这一时期出现了许多具有里程碑意义的AI应用:
- IBM深蓝对战卡斯帕罗夫(1997):经过多年开发,IBM的深蓝超级计算机在六盘比赛中以3.5:2.5击败了国际象棋世界冠军加里·卡斯帕罗夫,这是计算机首次在锦标赛条件下击败在位世界冠军
- 深蓝的技术细节:结合了专用硬件(30个RS/6000 SP处理器)和软件(使用α-β剪枝的搜索算法),能够评估每秒2亿个位置,搜索深度达到14步
- 社会影响:虽然这一胜利是计算能力和传统算法的胜利,而非真正的”智能”,但它极大地提升了公众对AI潜力的认识
- 机器人技术的进步:
- 索尼AIBO(1999):第一款大规模商业化的家用机器宠物
- iRobot Roomba(2002):第一款成功的家用自主清洁机器人
- DARPA无人驾驶汽车大挑战(2004-2007):推动了自动驾驶技术的发展
- 实用的语音和自然语言处理:
- IBM ViaVoice和Dragon NaturallySpeaking:1990年代末期的商业语音识别软件
- 统计机器翻译:基于大规模双语语料库训练的翻译系统开始超越基于规则的系统
- 问答系统的进步:为IBM Watson的后续开发铺平道路
- 智能搜索引擎:
- Google的PageRank算法(1996):由拉里·佩奇(Larry Page)和谢尔盖·布林(Sergey Brin)在斯坦福开发,革新了网页排序方法,考虑网页之间的链接结构
- 搜索引擎的语义能力:逐步从简单的关键词匹配向理解用户查询意图发展
深度学习革命(2010s-至今)
前奏:神经网络研究的坚持
在主流AI研究关注其他方法时,一小群研究者持续推进神经网络研究:
- 辛顿团队的受限玻尔兹曼机(2006):杰弗里·辛顿和他的学生提出了一种预训练深度神经网络的有效方法
- Yann LeCun在AT&T和纽约大学的工作:持续改进卷积神经网络架构
- 约书亚·本吉奥(Yoshua Bengio)在蒙特利尔大学的研究:探索深度学习理论和算法
- Andrew Ng在斯坦福的非监督特征学习研究:为后来在Google和百度的深度学习项目奠定基础
AlexNet与深度学习爆发
2012年是AI发展的一个重要转折点。在这一年的ImageNet大规模视觉识别挑战赛(ILSVRC)中:
- AlexNet的突破:由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton开发的深度卷积神经网络将图像分类错误率从26.2%降低到15.3%,比第二名好了近10个百分点
- 技术创新:AlexNet引入了多项关键技术:
- 使用GPU进行网络训练,大幅加速计算过程
- 使用ReLU激活函数代替传统的sigmoid函数,减轻梯度消失问题
- 使用Dropout技术防止过拟合
- 使用数据增强扩充训练集
- 行业影响:这一结果震惊了计算机视觉界,引发了深度学习的爆发性发展,许多公司和研究机构迅速转向这一方向
关键技术进步
深度学习的快速发展得益于几个关键因素:
- GPU计算:图形处理器的并行计算能力极大加速了神经网络训练
- NVIDIA CUDA平台(2007年推出)为深度学习提供了关键的硬件基础
- GPU训练相比CPU可以实现10-100倍的加速,使得更复杂模型的训练成为可能
- 专用AI芯片的出现:如谷歌的TPU(张量处理单元)进一步优化了深度学习计算
- 大数据:互联网产生的海量数据为模型提供了训练素材
- ImageNet数据集(包含1400万带标注图像)成为视觉模型的标准训练资源
- 社交媒体、搜索引擎和电子商务平台积累的用户数据为各类模型提供训练素材
- 众包标注平台如Amazon Mechanical Turk使大规模标注数据集成为可能
- 算法创新:解决了深层网络训练的关键难题
- 批量归一化(Batch Normalization,2015):由Sergey Ioffe和Christian Szegedy提出,通过规范化每层的输入分布加速训练并提高稳定性
- 残差网络(ResNet,2015):由微软研究院的何恺明(Kaiming He)等人提出,通过跳跃连接解决深层网络的退化问题,实现了超过100层的网络训练
- 生成对抗网络(GAN,2014):由Ian Goodfellow提出,通过生成器和判别器的对抗训练生成高质量样本
- 注意力机制(Attention Mechanism):最初用于提升神经机器翻译性能,后来成为Transformer架构的核心
- 开源框架:降低了开发门槛
- TensorFlow(2015年由Google发布):提供了灵活的数据流图编程模型
- PyTorch(2016年由Facebook发布):动态计算图使调试和原型设计更加便捷
- Keras:高级API简化了模型构建过程
- 开源模型库:预训练模型的共享加速了应用开发
深度学习的广泛应用
2010年代中期开始,深度学习在各个领域快速普及:
- 计算机视觉:
- 物体检测:R-CNN系列(2013-2015)、YOLO(2016)和SSD(2016)等算法实现了实时多物体检测
- 图像分割:SegNet、U-Net等架构提供了像素级别的图像理解
- 人脸识别:DeepFace(Facebook,2014)和FaceNet(Google,2015)将准确率提升到接近人类水平
- 图像生成:VAE、GAN等模型能够生成逼真的图像,DALL-E等扩展到从文本生成图像
- 自然语言处理:
- 词嵌入:Word2Vec(2013)和GloVe(2014)捕捉词语之间的语义关系
- 神经机器翻译:2014年后基于RNN的序列到序列模型取代了统计机器翻译
- 问答系统:基于深度学习的问答系统在SQuAD等基准测试上取得进步
- 语音技术:
- 语音识别:深度学习模型将错误率降低了30%以上,接近人类水平
- 语音合成:WaveNet(2016)等模型生成的语音更加自然流畅
- 智能助手:Siri(Apple)、Alexa(Amazon)、Google Assistant利用这些进步提供更好的语音交互
强化学习与游戏AI
强化学习在与游戏AI结合时取得了令人瞩目的成就:
- DQN玩Atari游戏(2013-2015):DeepMind开发的深度Q网络(DQN)能够学习直接从像素输入玩多种Atari游戏,有些甚至超过人类水平
- AlphaGo(2016):DeepMind开发的程序在2016年3月击败了世界围棋冠军李世石,这一成就比预期提前了10年
- 技术细节:结合了蒙特卡洛树搜索、监督学习和强化学习
- 后续发展:AlphaGo Zero(2017)完全通过自我对弈学习,无需人类棋谱,性能更强
- OpenAI Five(2018):在复杂多人在线游戏Dota 2中击败职业选手队伍,展示了AI在高度协作环境中的能力
- 创新点:能处理不完全信息、长期规划和团队协作,使用了大规模分布式训练
- 训练资源:使用了128,000个CPU核心和256个GPU,通过自我对弈进行了约180年的游戏经验学习
- AlphaStar(2019):DeepMind开发的程序在即时战略游戏《星际争霸II》中达到大师级水平
- 技术难点:处理不完全信息、大动作空间和长期规划
- 架构:结合了深度神经网络和多代理强化学习
这些游戏AI的突破不仅展示了AI的进步,更重要的是证明了AI系统可以在复杂、动态环境中制定有效策略,这对现实世界应用有重要启示。
大语言模型时代(2017-至今)
Transformer架构的革命
2017年是自然语言处理领域的转折点,Google的研究人员在论文《Attention is All You Need》中提出了Transformer架构:
- 核心创新:完全基于注意力机制(Attention Mechanism),摒弃了此前主流的循环网络结构
- 自注意力机制(Self-Attention):允许模型在处理序列时考虑所有位置,不受距离限制
- 多头注意力(Multi-Head Attention):允许模型同时关注不同表示子空间的信息
- 位置编码(Positional Encoding):解决了无序序列的位置信息问题
- 技术优势:
- 并行计算:不像RNN需要顺序处理,Transformer可高度并行化,大幅加速训练
- 长距离依赖:有效捕捉序列中远距离元素之间的关系
- 可扩展性:架构易于扩展到更大规模,性能随参数量增长而显著提升
- 最初用途:主要用于神经机器翻译任务,Google很快将其应用于翻译服务
预训练语言模型的兴起
Transformer架构推动了一系列预训练语言模型的发展,这些模型首先在大量文本上进行无监督预训练,然后针对特定任务微调:
- BERT(Bidirectional Encoder Representations from Transformers,2018):
- 由Google的Jacob Devlin等人开发,使用双向上下文信息进行预训练
- 预训练任务:掩码语言模型(预测被遮挡的词)和下一句预测
- 性能:在GLUE基准测试的多个NLP任务上取得突破性进展
- 影响:证明了通用预训练+特定任务微调的范式有效性
- GPT系列的开端(2018):
- OpenAI发布GPT-1(Generative Pre-trained Transformer),使用单向(从左到右)语言模型进行预训练
- 参数规模:1.17亿参数,在当时被视为大型模型
- 创新点:证明了无监督预训练加有监督微调的有效性
- XLNet、RoBERTa、ALBERT等改进模型(2019):
- 通过改进训练方法、增加数据量或优化架构,进一步提升了性能
- 研究界掀起了”预训练模型热潮”,几乎所有NLP研究都转向这一方向
规模化与惊人的涌现能力
随着模型规模不断扩大,研究人员发现了一个惊人现象:当参数量和训练数据达到某个临界点,模型会表现出”涌现能力”(Emergent Abilities)——这些能力在小规模模型中不存在,但在大规模模型中突然出现:
- GPT-2(2019):
- 参数规模:15亿参数,比GPT-1大约10倍
- 训练数据:WebText数据集,包含约800万个网页文档
- 能力:生成连贯、有条理的长篇文本,展示了基本的零样本学习能力
- 影响:由于对生成虚假信息的担忧,OpenAI最初只发布了小型版本
- GPT-3(2020):
- 参数规模:1750亿参数,比GPT-2大约100倍
- 训练资源:使用了超过1000个GPU,训练成本估计为数百万美元
- 涌现能力:在没有微调的情况下(零样本或少样本学习)执行各种复杂任务,如翻译、问答、摘要和简单编程
- 社会影响:震惊了AI界和公众,显著提高了对AI潜力的认识
- 其他大型模型:
- Megatron-Turing NLG(2021):由微软和NVIDIA合作开发,5300亿参数
- PaLM(2022):Google的5400亿参数模型,在推理、代码生成等任务上表现优异
- Gopher、Chinchilla:DeepMind的大型语言模型,探索了参数量与训练数据量的最佳平衡
大模型向多模态扩展
大语言模型的成功很快扩展到多个模态:
- DALL-E(2021)和DALL-E 2(2022):
- OpenAI开发的文本到图像生成模型
- 能力:根据自然语言描述生成高质量、创意丰富的图像
- 技术:结合了GPT-3风格的Transformer与图像生成技术
- Stable Diffusion(2022):
- 由Stability AI开发的开源文本到图像模型
- 创新点:使用潜在扩散模型,计算需求相对较低
- 影响:开源发布极大促进了图像生成技术的普及
- CLIP(2021):
- OpenAI的视觉-语言模型,通过大规模对比学习连接文本和图像
- 能力:理解开放世界的图像,零样本迁移到新任务
- Flamingo(2022):
- DeepMind的视觉-语言模型,可处理图像、视频和文本输入
- 特点:可以根据视觉内容回答问题或生成相关描述
- Sora(2024):
- OpenAI的文本到视频生成模型
- 能力:根据文本提示生成高质量、长达一分钟的视频
- 技术突破:能够维持时间和空间上的一致性
GPT时代的进一步发展
OpenAI的GPT系列继续引领大语言模型的发展:
- InstructGPT与GPT-3.5(2022):
- 通过人类反馈的强化学习(RLHF)优化模型,使其更好地遵循人类指令
- ChatGPT(基于GPT-3.5)于2022年11月发布,迅速获得超过1亿用户,成为历史上采用最快的消费技术
- GPT-4(2023):
- 多模态能力:可以处理图像输入和文本输出
- 性能提升:在多个专业考试(如律师资格考试、医学执照考试)上接近人类专家水平
- 上下文窗口扩展:能处理更长的输入文本(最初为8K,后扩展到32K、128K tokens)
- 思维链能力增强:展示了更强的推理和问题解决能力
- Claude系列模型(2023-2025):
- Anthropic公司开发的大语言模型系列
- 特点:强调对齐性(Alignment)和安全性,更长的上下文窗口
- 发展:从Claude 1到Claude 3系列,性能不断提升
- Llama系列(2023-2024):
- Meta公司开发的开源大语言模型
- 影响:Llama 2的开源发布大大促进了语言模型研究的民主化
- 性能:较小参数量(7B-70B)但性能接近更大的封闭模型
大模型应用的爆发
大语言模型的应用范围迅速扩展:
- 会话式AI助手:
- ChatGPT、Claude、Bard/Gemini等产品改变了人机交互范式
- Microsoft Copilot、Google Duet AI等产品集成到办公软件生态系统
- 消费者采用速度前所未有,ChatGPT成为史上增长最快的消费应用
- 代码生成与辅助编程:
- GitHub Copilot(2021):基于Codex(GPT模型变体)的编程助手
- 能够根据注释和上下文生成代码,完成函数,提供推荐
- 影响:开始改变软件开发流程,提高开发者生产力
- 搜索增强生成(RAG):
- 结合传统搜索与生成AI的优点,减轻幻觉问题
- Bing Chat(现Microsoft Copilot)、Perplexity等产品将这一技术商业化
- 企业专有模型:
- 各行业开始构建针对特定领域知识的定制模型
- 医疗(如Mayo Clinic的MedLM)、法律(如CaseLawGPT)等领域出现专业化应用
大模型的当前挑战
随着大语言模型的迅速普及,多项重要挑战显现:
- 幻觉(Hallucination)问题:
- 模型可能自信地生成虚假信息
- 研究方向:检索增强生成(RAG)、不确定性标识、自我修正
- 长上下文理解:
- 早期模型的上下文窗口有限(如2048 tokens)
- 最新进展:模型上下文长度不断扩展(GPT-4 Turbo达128K,Claude 3达200K)
- 挑战:即使有长窗口,模型对远距离信息的有效利用仍有限制
- 推理能力的局限:
- 复杂多步推理时易出错
- 改进方向:”思维链”(Chain-of-Thought)提示、多步推理框架
- 计算资源需求:
- 训练大模型需要巨大的计算资源和能耗
- 推理成本限制了某些应用场景
- 研究方向:模型蒸馏、量化、稀疏激活等提高效率的技术
- 隐私与数据安全:
- 训练数据可能包含敏感信息
- 提示注入和模型提取攻击引发安全担忧
- 对策:隐私保护训练方法、更安全的部署架构
AI对软件开发的影响
开发者新工具箱
作为软件开发者,AI已经成为我们工具箱中的重要组成部分:
- 代码辅助:
- 代码生成:根据注释或需求描述生成完整函数或模块
- 代码补全:实时提供上下文相关的代码建议
- 代码解释:帮助理解复杂代码库
- 代码转换:在不同编程语言间转换代码
- **示例:GitHub Copilot、Codeium、CodeWhisperer、Tabnine等
- 自动化测试:
- 测试用例生成:自动创建单元测试和集成测试
- 测试数据生成:生成各种边缘情况的测试数据
- 探索性测试:AI驱动的自动化UI测试
- **示例:Diffblue Cover、Applitools、mabl等
- 智能调试:
- 错误根因分析:快速定位问题源头
- 自动修复建议:提供潜在的修复方案
- 性能瓶颈识别:分析代码性能问题
- **示例:Microsoft’s Visual Studio IntelliCode、Rookout等
- 文档生成:
- 代码注释生成:自动创建函数和类的文档
- API文档生成:从代码自动生成完整API文档
- 用户指南撰写:生成最终用户文档
- **示例:Mintlify、Outline等
AI驱动的软件开发流程
AI正在改变软件开发的整个生命周期:
- 需求分析阶段:
- 通过NLP分析用户故事和反馈
- 自动识别需求中的矛盾和模糊点
- 生成更完整的需求规格说明
- 示例工具:JIRA的AI功能、Grammarly for Work
- 设计阶段:
- 生成UI/UX原型和线框图
- 推荐适合特定需求的架构模式
- 评估不同设计方案的优缺点
- 示例工具:Uizard、Figma的AI功能
- 编码阶段:
- 代码生成和补全辅助
- 实时代码质量和最佳实践建议
- 自动重构和优化建议
- 示例工具:GitHub Copilot、JetBrains AI Assistant
- 测试阶段:
- 自动化测试生成和执行
- 智能测试用例优先级排序
- 缺陷预测和分类
- 示例工具:Testim、Functionize
- 部署与维护阶段:
- 预测潜在运行时问题
- 智能化运维和监控
- 用户反馈自动分析
- 示例工具:Datadog的AI功能、PagerDuty
具体案例:AI辅助软件开发的成功故事
- Microsoft内部使用Copilot的经验:
- 23%的代码由AI生成
- 开发者报告完成任务的速度提高了55%
- 87%的开发者表示AI帮助减少了认知负担
- JPMorgan Chase的代码助手应用:
- 自研系统”COIN”(Contract Intelligence)
- 节省了36万小时的法律文件分析时间
- 极大降低了错误率
- Netflix的个性化推荐系统开发:
- 使用AI自动化测试和优化
- 显著缩短了A/B测试周期
- 提高了开发团队的迭代速度
未来展望
AI技术仍在高速发展,未来几年我们可能会见证:
- 更高效的模型:
- 小型但高效的模型(Small Language Models, SLMs)
- 混合专家模型(Mixture of Experts, MoE)减少计算需求
- 边缘设备上的本地AI能力
- 多模态融合的深化:
- 文本、图像、视频、音频的无缝集成
- 跨模态理解和生成能力提升
- AR/VR与AI的结合创造新交互范式
- 人机协作的深化:
- AI不是替代开发者,而是成为开发者的”副驾驶”
- 更自然的协作界面(如对话式编程)
- 开发者保持创意和判断力优势,AI处理重复性任务
- 领域特化AI:
- 针对特定行业和任务优化的AI解决方案
- 垂直领域知识与通用AI能力的结合
- 特定语言和框架的专业化助手
- AI开发的民主化:
- 更多无代码/低代码AI开发平台
- 模型定制能力的普及
- 更多开源和可访问的AI工具
- AI系统开发的新范式:
- 基于大型语言模型的代理(Agents)系统
- 自主规划和问题解决能力
- AI辅助的系统架构设计
结语
从图灵的理论构想到今天的大语言模型,AI已经走过了漫长而曲折的发展道路。这个历程充满了理论突破、技术创新、商业化浪潮与研究低谷的交替。今天,我们站在技术爆发的时代,见证AI以前所未有的速度改变软件开发和几乎所有行业。
作为软件开发者,我们有幸生活在这个AI快速演进的时代,不仅能利用这些技术提升工作效率,还有机会参与创造下一代AI应用。理解AI的历史,能让我们更好地把握其本质,避免重蹈历史的覆辙,并在未来的发展中做出更明智的技术选择。
虽然AI已经取得了惊人的进步,但它仍然面临着重要的挑战,如真正的理解、常识推理、伦理问题等。这些挑战同样也是机遇,为下一代研究者和开发者提供了广阔的探索空间。
在接下来的系列文章中,我们将更深入地探讨AI的各个分支、核心概念以及如何将这些技术实际应用到软件开发工作中,帮助您在AI时代保持竞争力并创造更大的价值。
推荐阅读:
- 《人工智能:一种现代方法》- Stuart Russell & Peter Norvig
- 《深度学习》- Ian Goodfellow, Yoshua Bengio & Aaron Courville
- 《Transformer架构的视觉指南》- Jay Alammar博客
- 《AI新篇章:GPT与大语言模型实战》- Chip Huyen
- 《开发者视角下的大模型》- Simon Willison